Tag: IBM
-
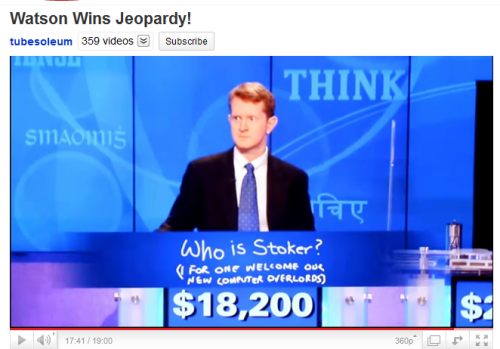
Watson Wins Jeopardy
Ken Jennings graciously concedes losing to IBM’s Watson computer on the final day of the three day Jeopardy tournament. More details on the research behind the experiment on my earlier post.
-
IBM Watson on Jeopardy
In a brilliant piece of PR, IBM Research stormed back on the scene matching their artificial intelligence computer, Watson, against top contestants of the popular American game show, Jeopardy. On February 14, 15, and 16 Watson’s competes against two humans on live television. According a piece on Wired’s Epicenter blog, 25 IBM scientists spent four…
-
IBM wants to play too
It was a busy day for Bay Area locals involved with startups. First there was the Under the Radar conference which featured a number of startups looking for a little extra attention. Later in the day, Business 2.0 gave a party for all the folks they recently nominated to a list they’re calling the Next…
-
Big Blue Blogging Army
It’s been known for some time that there are hundreds of bloggers toiling away inside IBM and representing the company to their various audiences. This week, IBM announced support for this grassroots movement and is encouraging any of its 320,000 employees to take up the blog. “We’re not telling our people what to say, we…
-
IBM
There is a very interesting theory about why IBM shed their vaunted ThinkPad & PC hardware division to China’s Lenovo. Attributed to the Petrov Group, in a Business 2.0 article, the theory is that IBM would use it’s partnership (IBM still owns a percentage of Lenovo) to enter the China market with a low cost,…
-
Big Blue Masala
IBM will release a new corporate search engine, the “DB2 Information Integrator” (code-named Masala) tomorrow reports CNet and eWeek. The information integrator is able to do this because it can search rapidly across multiple databases, including relational and non-relational databases and structured and unstructured data such as text files, word documents, Adobe Acrobat files, video…