Tag: New York Times
-

China Tracking
A new video from the New York Times outlines not only the scale but sinister evolution of state-sponsored data collection.
-

Native Podcast Players
The New York Times app added a native podcast player that does an excellent job of complimenting their news rather than competing with it. The player was launched to support The Daily, their flagship news show. What is really interesting about this player is that it lets the user continue to browse while listening. Tap…
-

Back when News was Physical
etaoin shrdlu are the first line of letters on a linotype keyboard, arranged based on frequency. The phrase is used to mark the end of a column. It is also the title of a short documentary about the last run of the linotype machines at the New York Times on July 2, 1978. There are all…
-
More nytimes.com takeovers
They’re at it again. Another editorially-obfucating takeover.
-
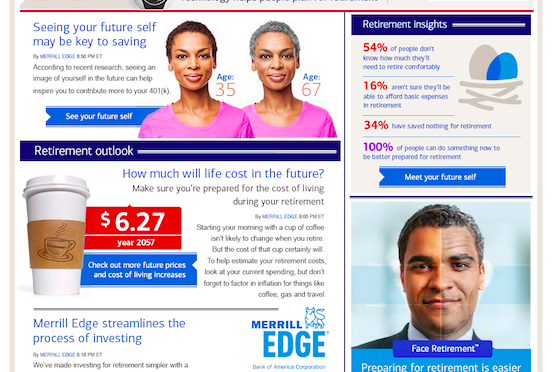
To Give and Not Receive
This afternoon New York Times readers were assaulted by a full page takeover that unfolded across the front page effectively roadblocking the news of the day with a “special report” layout that was both interruptive and offensive. If this is where they are going with their native advertising, I do not like. All publishers need…
-
YouTube as a Search Engine
My son was featured in yesterday’s Sunday New York Times in an article (At First, Funny videos. Now, a Reference Tool) about the unforeseen use of YouTube as a research tool. We all associate videos with entertainment but Tyler has taught me that with the addition of meta-data and micro-chunked content, it’s possible to use…
-
Another Cool New York Times Hack
Robert Langman left a comment on my previous post about meta-data at nytimes.com with a link to a couple of cool mashups that use keywords on the older archive of New York Times material, the paper from 1851 through the early 1900’s. Check it out here.
-
Open Sourcing the New York Times
The New York Times has a blog about open source projects and today they shed a little more light on all the wonderful metadata that they make available for folks like Dave Winer to build upon. I sense an open source news hack day coming on.
-
Go on, cheat a little
Yahoo has joined up with the folks at the New York Times crosswords to promote the new Search Assist feature with a contest. The idea is that you fill the puzzle out successfully and you too can be entered into a drawing for one of five trips to Hawaii. Thing is, this thing is a…