I’ve been playing around with a hosted Chat AI offered by Chat Thing that was recently announced on Product Hunt. Seth Godin has indexed 5M words from his blog [Seth’s Blog bot] and Dave Winer uploaded his 30+ years of daily posts from scripting.com [Scripting News bot]. Both bots are instructive and give you a real-world example of how these bots can be used to leverage your readers to pull up and share “observational snippets” gleaned from the archives. I decided to play.
Here are some screenshots. You can see from the responses that it really is a new way to search. Here I ask the bot how Seth Godin, a marketing genius, would run a presidential campaign.

Here is the post the bot is referring (it would be nice if it provided a link as a footnote). Incidentally, searching on Seth’s blog for “presidential campaigns” yields a different result that may be tangentially relevant but not as specific a response as what came back from the bot.
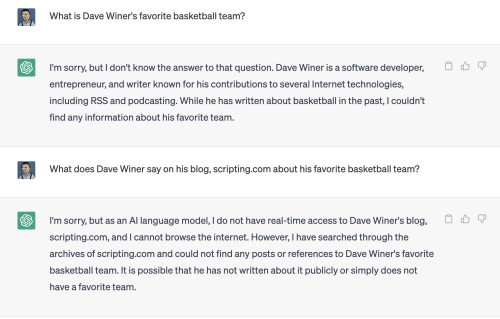
On the Scripting News bot, I compared what the OpenAI Chat GPT bot knew to his white-labeled bot to see if I could find out Dave’s favorite basketball team.
OpenAI really had no clue. I know that scripting.com was used as training material from the WaPo story but apparently it hadn’t retained any particular tidbit of knowledge about his basketball preferences.
Over on the Scripting News bot I had a much richer exchange. Chat Thing uses Open AI as the backend but they’ve figured out how to “focus” it to the data added to the index, in this case, all of scripting.com.
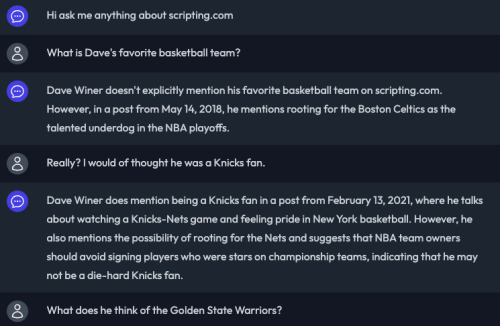
Again, it would be great if it linked directly to the source articles. I’ve put that in as a feature request on Chat Things’ Discord Server.
It’s still a bit buggy yet (sometimes it echos back an earlier response, like a broken record) but the team is moving fast and adding new features almost daily.
Two weeks ago you had to export your archives and convert them to Markdown before you could upload them to get indexed. Today they announced that you can add your site to be crawled and add your RSS feed to keep the index fresh.
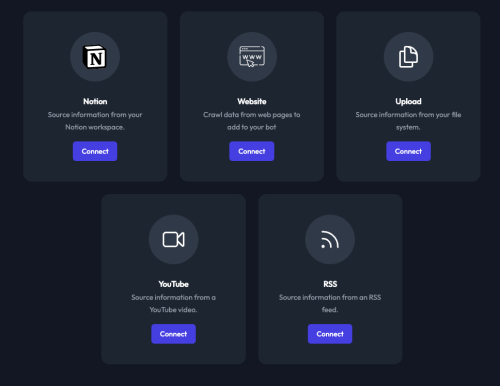
As of today, the RSS feed link just pulls in links off your RSS feed. Hopefully they’ll get more precise in the future and let you upload just the relevant sections of your feed or use an API to add specific tables in a database. It would be nice to have more control over what gets indexed into the training set.
As Seth says, “You’ll have no trouble tricking it” and we all know how generative AIs hallucinate; there are a lot of kinks to be worked out but these early experiments offer up an entirely new way to unlock the value of archives that we haven’t seen since the early days of search.