Last week, I was double-booked in conferences. Wednesday & Thursday I was in Philadelphia for the beginning of the Online News Association conference, a gathering of journalists who work with words online. Friday & Saturday, I was in Washington DC for WordCamp, a gathering of people who work with WordPress, the CMS software that powers many of the websites journalists use to publish their news online.
Hopping between these two worlds, the editorial and technical, gave me a unique perspective of the change sweeping online media. Everyone agrees that AI Chat Bots, specifically generative AI from Large Language Models (LLMs), will have an enormous impact on what we read online. But, depending on who you’re talking to, it’s going to result in either the horror or something wonderful.
It’s still very early but a long Amtrak train ride home gave me some time to project out where we’re headed and ponder what we might need to make it work in a way that both publishers and AI Chat Bot companies feel comfortable.
Those that fear AI view it as something that will strip mine websites of their facts and process them into the bland, robotic responses that power AI Chat Bots. This characterization echoes the publishing industry’s initial reactions to Google search. In 2006, French and Belgium newspapers demanded to be removed from Google News only to come back begging for inclusion in 2011 after they experienced a precipitous drop in traffic.
Are we seeing the same thing play out with AI? Isn’t an AI chat bot just the conversational form of the Google SERP? Microsoft Bing Chat and Google Bard are crawling the web for tidbits to power their conversational engine. Concern about Bing and Bard abstracting facts without sending users back to a publisher’s site exposes a flaw in the publishing business model where a website is compensated by readers looking for answers on a page in adorned with advertisements designed to distract and harvest attention.

It’s time to upgrade this business model. Instead of asking people to browse a bunch of search links, AI Chat Bots bring information to the reader, aggregated, summarized in a conversational tone. To a certain extent, this is an evolution of what has been happening for years.

When Google Knowledge Graph launched in 2012, many publishers felt the Knowledge Panel (as it came to be known) did not provide enough attribution. Sound familiar?
If the reader no longer goes to the publisher’s site, they will end up spending time with the product providing the answers, not the source. Back then it was Google, today, it’s the AI Chat Bot.

The AI Chat Bot is the latest step in a journey that was started a long time ago. Bringing answers into a conversational UI is just improving on user experience for those in search of quick answers to their question.
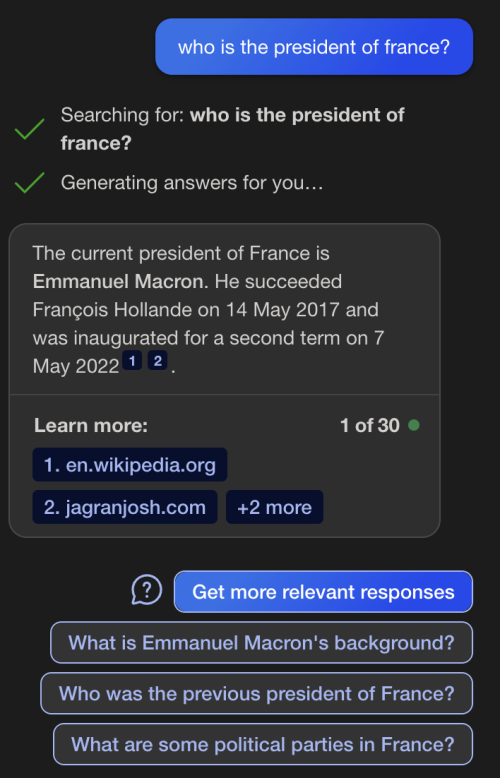
This new conversational UI is under rapid development. I’m not even sure a conversational is where we’ll end up. Microsoft is leading the way with Bing Chat AI results sprinkled with attributions that give credit and links back to the source material. From what I can tell, Microsoft is also is paying for this attribution in an early experiment in what I would call “licensing of facts.” Google’s Bard is following Microsoft’s lead and is also starting to add attribution to its SGE results, something that was missing at launch. I’d be curious to know if they are paying publishers for these links.
Microsoft is embedding Bing AI in not only into their Edge Browser but has also announced extensions for Chrome and Firefox. Bing Chat is also available as an Enterprise service as well as on their mobile app and Skype.
The pressure is on and Google is responding in kind with their version of generative AI chat, SGE, which is running in Google Labs.
If generative AI is the next generation of search, I can think of a number of things that are needed to build a relationship between the publisher and AI vendor that is transparent, trustworthy and thus, sustainable. Allow me to riff a bit.
Honor Robots.txt
Open AI already announced that they would honor robots.txt and not crawl sites that declare themselves off limits. This is now extended to optimize which sections of your site you want to make available to the AI Chat Bots. The New York Times, CNN, and others are already adopting this method to control what they make available.
This is a step in the right direction as it builds trust but more granular control over what is made available for the crawl is necessary. Within a restaurant review, maybe the address & phone number will be valued one way while the reviewer’s opinion valued another way.
Sitemaps for AI
A sitemap is a file that instructs a web crawler where to look for new pages. A sitemap for AI could be an intentional declaration by a site owner of what specific facts and information you want to make available and what link you want to serve up for the attribution. Addresses can be fielded and formatted one way, quotes another way so that they travel along with the name of the person quoted.
Ads.txt was developed to make programmatic advertising more transparent. What I’m thinking of is something in between a sitemaps.xml and ads.txt, a lightweight, machine-readable way for publishers to declare what they make available to the Chat Bot crawlers.
Real time Fact Exchange
The technology that enables the real time auction for ad impressions on sites in milliseconds is some the most impressive technology developed for the internet in the past couple of decades. The incredible revenue machines of the ad industry have fueled the advancements in this technology.
It’s time for a similar exchange for the facts which will be the new commodity. When looking for answers via a chat bot that has access to everything, maybe the deciding factor is the quality of the information or the party that is making it available. If every fact is distinct in the aforementioned Sitemap for AI, why not also attach a value to that fact that can inform the AI chat bot which information it can afford to share. If it’s a high value reader then more expensive information from higher quality sites might be presented. We are already headed down this path as both search results and social media links that go to paywalled sites attempt to capture subscriber budget.
Is it finally time to create a marketplace of micro-transactions brokered by the Chat Bot UI? Instead of subscribing to a bunch of subscription sites, maybe the AI is where “pay” for tidbits of information with either advertising or payment tiers and that revenue is shared by the Chat Bot companies with the companies providing the information?
In order for the Chat Bot AI ecosystem to grow, the publishers need to be fairly compensated and the Chat Bot vendors need a marketplace for the content they need to provide a quality experiences. Maybe the Real Time Fact Exchange is a far-fetched but I would have never thought the simple banner ad would have evolved into the complex ecosystem we have today.