I was fortunate to be invited last week to the kick off meeting for an IAB Tech Lab task force dedicated to establishing a framework for Monetizing the Open Web in the age of AI.
The accelerated use of tools such as OpenAI’s Chat GPT, MSN’s CoPilot and Google’s AI Overview has precipitated a re-thinking of how publishers are compensated for their work. While the conversation is only just beginning, this group outlined concrete suggestions to the challenges ahead.
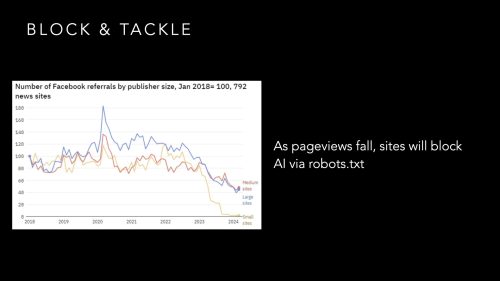
Publishers must work together to stem the flow of unlicensed content.
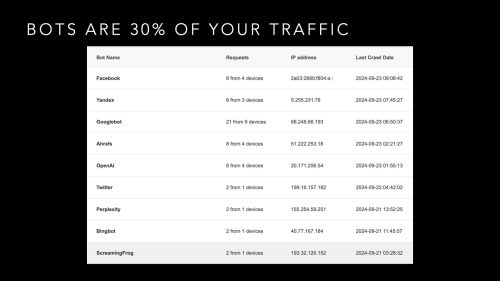
As long as information is readily available and free, there is no incentive to drive demand. Unless you limit supply, you cannot derive value. Content Delivery Networks (CDN) such as CloudFlare and Fastly are on the front lines as they see the majority of requests & responses across their networks. They have noted the sharp increase in AI-bot traffic and have the expertise in the blocking and tackling of the thousands of bots and spiders.

Publishers in the room are anticipating a world where the value of a search result on Google is less than the value of licensed access from an AI Agent. In such a world, it would be prudent to default to denying access to all crawlers in favor of direct access by verified, registered readers or licensed partners.
Old methods such as robots.txt and user-agent/IP address blocking filters are readily ignored or spoofed by long-tail startups scrambling to serve their users. More secure methods are necessary. “Get a better lock on your door.” says Jon Roberts, Chief Innovation Officer at DotDash Meredith.
Establish a marketplace for publisher information that can scale to serve AI Agents.
While CloudFlare’s Cost-Per-Crawl implementation redirects crawlers to a 402 HTTP error page to redirect AI developers to licensing information, TollBit and Dappier are building the first marketplaces for publisher libraries as a proof-of-concept as a bridge from the search engine results of the past to the marketplace of the future.
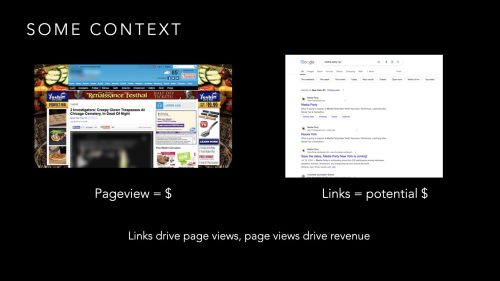
A search for the past 25 years returned 10 blue links of which a human might read 1 or 2 links. This referral traffic was the currency of the old internet. This attention could be monetized any number of ways.
Google owned this marketplace.
Now imagine a world where a query by an AI Agent may spawn 20-50 queries of which *every* article is scanned and synthesized into a single response. Ads and subscription funnels on these pages are ignored. There needs to be a different pricing model for this traffic. Source material will not be a “page” but could be a snippet of video, a schematic blueprint, a sound bite, or a product spec. The pricing model in this “marketplace of everything” needs to recognize and support dynamically pricing requests based on who is requesting it and in what format, all in real-time.
The programmatic advertising ecosystem which has been the engine driving the growth of online publishing for the past 25 years was subsidized by advertisers bidding for a reader’s attention on a web page. An entire tech-stack was built to serve up the right ad for the right audience at the right time, all in under 500 ms.
With AI Agents, you have readers paying directly for content with their subscriptions (Chat GPT Pro is $200/month) and the AI Agent is acting as a proxy on their behalf. Once publishers have successfully shut off the free flow of their content, accurate, reliable, and up-to-date information will accrue value. In this world, there will be need for a real time marketplace to handle the access and metering of content and this system will need to be built to the same scale and performance of the programmatic advertising platforms of today.
No one owns this ecosystem.

Tokenization – core components to a market
The final step, once you have established a way to meter (cost-per-crawl, cost-per-query or some other subscription model) access to a publisher’s library, is to establish a standardized way to track and count content as it travels through the ecosystem from a publisher to the AI platform.
Tokenization is this final step. Once an AI has asked for something, the response needs to be tokenized in such a way to properly attribute credit as well as track the usage of that content not only to the initial query but in all future derivative uses.
ProRata has a working implementation of this tracking in their Gist Answers, distributed search widget. “If you can track it, you can charge for it.” they say as their IP is focused on the attribution of AI responses from their network of publishers.
TollBit has one-time use tokens for access and are setting up a system where an AI Agent can query for information, inquire about pricing, and generate and receive a token to retrieve the information as needed, on demand.
All these are approaches to the same problem and my company, SimpleFeed, aims to participate in the delivery of publisher content, whether it be tokenized, vectorized (to assist in discovery), or otherwise value-added with filtering and meta-data augmentation as we have been doing for 20+ years.
I look forward to staying engaged with the individuals and companies that were gathered for this workshop. AI summarization is rapidly tearing down a business model that has worked for decades. Unless there is an agreed upon business model that is accessible to all players including small publishers and long-tail AI startups, we may lose the diversity of opinions and perspectives that have given us the open web we currently enjoy.
It makes sense that IAB, an industry group that helped establish standards around online advertising, is taking the first steps to establish standards around the AI Agentic web of the future. I thank them for taking this first important step of getting all the players in the room together and publishing the first framework for publisher content monetization and brand content management for LLMs and AI agents.
Publishers underwrite new projects based on forward-looking financials. If nothing is done to improve the economics of publishing online today, the investigative reporting of the future will not be funded and we will all be poorer for it.