
Ken Jennings graciously concedes losing to IBM’s Watson computer on the final day of the three day Jeopardy tournament. More details on the research behind the experiment on my earlier post.
a blog by Ian Kennedy
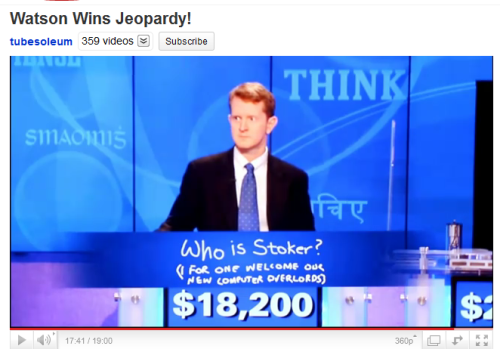
Ken Jennings graciously concedes losing to IBM’s Watson computer on the final day of the three day Jeopardy tournament. More details on the research behind the experiment on my earlier post.
In a brilliant piece of PR, IBM Research stormed back on the scene matching their artificial intelligence computer, Watson, against top contestants of the popular American game show, Jeopardy. On February 14, 15, and 16 Watson’s competes against two humans on live television.
According a piece on Wired’s Epicenter blog, 25 IBM scientists spent four years building Watson. “Powered by 90 IBM Power 750 servers, Watson uses 15 terabytes of RAM, 2,880 processor cores and can operate at 80 teraflops, or 80 trillion operations per second” The database of content upon which Watson draws its “knowledge” is from over 200 million pages from reference texts, movie scripts, entire encyclopedias, as well as, Wikipedia.
How did Watson do?
After the first day, Watson is tied with Ken Jennings for the lead at $5,000, beating out Brad Rutter who has $2,000. For details on the game and some behind the scenes of what was going on, listen to the interview with Stephen Baker on Arik Hesseldahl’s post on All Things Digital.
Footage from a practice round back in January below.
More details at the IBM Watson mini-site and a documentary on Nova, Smartest Machine on Earth.
It was a busy day for Bay Area locals involved with startups. First there was the Under the Radar conference which featured a number of startups looking for a little extra attention. Later in the day, Business 2.0 gave a party for all the folks they recently nominated to a list they’re calling the Next Net 25.
I didn’t get a chance to attend either of these events but I did get the chance to get the scoop from folks that did attend (including Jeff Clavier) at a dinner hosted by IBM. Willy Chiu is a VP in the High Performance, On Demand Solutions Software Group and runs an applied development lab at IBM’s research campus down south of San Jose. The dinner could be best described as a "salon" in the spirit of the gatherings hosted in the late-1800’s. The topic was broadly "Web 2.0 in the Enterprise" and covered topics such as applying the concept of mashups to corporate application development.
IBM clearly sees the excitement in consumer application development going on and is trying to understand how they can better participate in the ecosystem and introduce the concepts to the enterprise. Anyone who has worked in a large company knows that there is a growing gap between the tools available to an individual working on the internet and a worker dependent upon corporate systems.
Why does it take less than a second to get to a results page on Yahoo while it takes sometimes minutes to search for something on your hard disk. Why is it so easy to locate someone with expertise on the web but so difficult when you need to resort to often out-of-date company directories? Rod Boothby’s been doing a lot of thinking about this and has some good ideas.
IBM knows there is a big opportunity to bring best practices being used on the web today (interative development, modular and addressable APIs & information, AJAX/realtime UI feedback) and bring them to their large enterprise clients in concert with some of these new startups and are struggling with figuring out how to make this happen while still adding value.
It was interesting because I’ve been listening to a talk that Clayton Christensen (Innovator’s Dilemma) gave back in 2004 and he addresses some of the very things that IBM is grappling with at this moment when faced with disruptive technologies. As the startups such as Joyent and Zimbra repackage and improve upon components such as shared address books and group calendaring that used to be the sole domain of companies such as Microsoft and IBM, these bigger companies need to realize they can no longer extract value by selling a standard Exchange license. The value is moving up the stack and is going to move to applications that work on top of commodities such as corporate email and calendars. Consulting services around integration is one way to keep creating value, extended services such as mobile access and specialty hardware devices is another.
The Clayton Christensen talk on Capturing the Upside is worth a listen. Download it to your iPod. It’s a little over an hour but worth it if you’re stuck in traffic. Clayton’s voice has a calming effect.
It’s been known for some time that there are hundreds of bloggers toiling away inside IBM and representing the company to their various audiences. This week, IBM announced support for this grassroots movement and is encouraging any of its 320,000 employees to take up the blog.
“We’re not telling our people what to say, we could never do that. It’s a natural extension of the work IBM has been doing for many decades, in establishing its expertise in key areas,” Jim Finn, senior communications executive at IBM told Silicon Valley Watcher.
Tom Forenski of the SiliconValleyWatcher describes the move as something that, “would hlep establish IBM’s thought leadership in global IT markets.” In related news, James Snell of IBM has posted the IBM corporate blogging policy which is a good read for anyone else thinking of launching similar “massive corporate wide blogging initiatives.”
There is a very interesting theory about why IBM shed their vaunted ThinkPad & PC hardware division to China’s Lenovo. Attributed to the Petrov Group, in a Business 2.0 article, the theory is that IBM would use it’s partnership (IBM still owns a percentage of Lenovo) to enter the China market with a low cost, Linux-based PC platform.
As Petrov puts it, China “is a command economy and is price sensitive.” It is also projected to surpass the United States as the biggest PC market by 2010. In fact, in that year, the Chinese are expected to buy 180 million PCs, while the developed world will buy 150 million. If IBM, through its new partner Lenovo, could establish cheap Linux desktops as an acceptable alternative to Windows machines in China alone, it would cut Microsoft’s cash flow from a much-needed growth market. At the same time, it would teach a new generation of IT managers in China that since Windows isn’t a necessity, Microsoft products aren’t needed on servers either. (Subtext: Buy IBM.)
If this is indeed the scenario that folks in Armonk have dreamed up, it’s absolutely brilliant.
IBM will release a new corporate search engine, the “DB2 Information Integrator” (code-named Masala) tomorrow reports CNet and eWeek.
The information integrator is able to do this because it can search rapidly across multiple databases, including relational and non-relational databases and structured and unstructured data such as text files, word documents, Adobe Acrobat files, video or audio files, according to Jones.
“To gather this information up today, they might have to use multiple searches,” Jones said. DB2 Information Integrator can replace all of these searches with a single search that gathers all of the types of information to answer a single question, he said.
Sounded like a pretty tall order to me. I’ve heard of connectors that can search the closed-caption text of a video but audio has no such meta-data. A scan of the IBM website for Masala doesn’t help either. I then happened upon this IBM Research site that shows early attempts to automatically categorize images on MPEG-7 video files. Once categorized, you can then query the meta-data attached to each image.
Some further work is needed to iron out the kinks. In the example, looking closer you can see that both Janis Joplin and Peter Jennings were tagged as “animals”