Om blogged some thoughts after 12 years of blogging and came to the conclusion that one’s blog is one’s digital home. It is not only where you start new conversations, it should also be where you aggregate and archive the fruits of conversations you participate in out on various social web platforms.
And while I embrace every new social platform with gusto, I find it frustrating that my point of view is spliced across various networks. I think the blog is the one that ties it all together — a central location where you fit together all the Lego pieces.
– Om Malik on the role of blogs, In 12 years of blogging, the more things change, the more they stay the same
Most blog platforms support widgets which can bring in streams of your updates from various services. It started with flickr, delicious, and last.fm but soon all the other social services joined in. Twitter widgets are the latest incarnation of the sidebar social widget which you can install today.
Before Facebook arrived to suck out all the oxygen from social aggregator services there were a number of services, most famously FriendFeed, which would pull in all your updates from across the web on to one page. MyBlogLog was another.
While I was working with the MBL team we were hard at work pushing forward the aggregation feature but with one unique twist. While you could go to your MBL page and see anyone’s profile along with their newsfeed (we called it “New with you”), we also gave you the option to grab the javascript that let you run this widget on your site as a “full page widget”
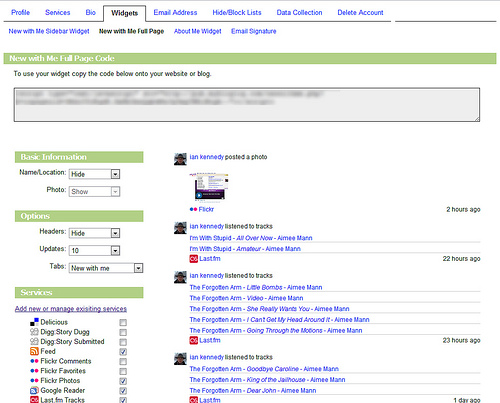
I have yet to see a suitable replacement for this code. I run a plugin called Social Stream on my site but it’s doesn’t quite do the trick. Efforts such as the Locker Project and it’s hosted cousin Singly seem to have lost momentum.
The web is a collection of digital artifacts. Text, photos, sound files are by-products that are digitized and indexed. We use search engines to locate these artifacts but no one has built a way to tie all these artifacts back to their owner. Until you tie the collective digital artifacts of a person together in a unified way and follow it over time, you don’t really know that person.
I’ve written about this before but the pendulum swings back and forth between the convenience of social networks on the one hand and the independence of owning your own domain/blog on the other.
Which Network do I Use?
- Instagram Direct vs. Snapchat
- Facebook vs. Twitter
- AIM or Yahoo Messenger or MSN Messenger
Once the commoditization of the latest communication protocol has proliferated, the pressure to consolidate identities pushes the updates to a neutral platform which is always the blog.
This is why I always maintain my own domain and host my own archives. Everwas.com is a digital representation of my life, my virtual self. I have posts about my marriage, my children, my career, observations on places I’ve lived – all other matter of stuff. It’s too important to put under another brand’s name, it’s too precious to be held ransom by anyone’s monetization strategy.
Go ahead, play around with the latest social shiny thing but be sure to save the best for your blog. You’ll be thankful you did.
Further reading:
- IndiewebCamp is organizing meetups for like minded folk to talk about the importance of self-hosting identity. They have a good reading list.
- Own your Own Web by Marco Arment
- On Owning your own content by Aral Balkan
#indieweb