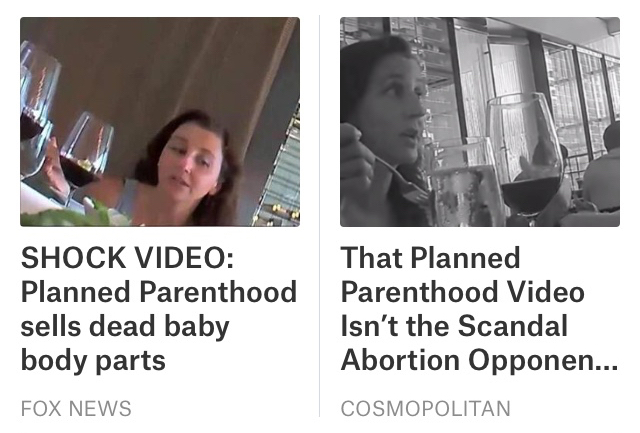
There are at least two sides to every story. The Planned Parenthood videos were a polarizing topic that monopolized the news cycle several weeks ago. How do you teach an algorithm a point of view? How do you optimize for discovery and strike the right balance for diversity while avoiding duplication?
SmartNews is a news aggregation app driven by machine learning algorithms. The platform is tuned for discovery (as opposed to personalization). After using it regularly, I began collecting screenshots of my favorite examples when the app taught me something new or showed me two items side-by-side that suggested a subtle intelligence.

The science and application of artificial intelligence to personalization is well understood. From Amazon’s people-that-bought-this-also-bought-that to Pandora’s Music Genome Project, software has been recommending what you’ll like next best based on what you’ve liked so far for years.
The new frontier in artificial intelligence is machine learning. Companies such as Spotify and Netflix are hard at work trying to predict future tastes based on an evolving understanding of collective tastes. Sure, learning assumes knowledge of the past, but projecting that learning into the future is much harder as you build a model based on an understanding of something that does not exist. Rather than showing you something we know you’ll like based on what you liked in the past, machine learning discovers things you didn’t know you would like.
First a little context. SmartNews, while deceptively simple, has a lot going on under the hood. At any time, the SmartNews app shows around 250 headlines across 8 categories. These headlines are selected from millions of stories that are scanned each day. In order to ensure that the stories featured in the app are the most important and interesting, a number of things must take place.

After harvesting URLs, the text of each article is run through a classifier that examines things such as the headline, author byline, publication date, images and video embeds. These pieces are analyzed by a semantic engine that extracts data so the algorithm can map the article to a topic cluster and place it into the appropriate subject category. (I wrote about how this is done in an earlier post)
Importance estimation is where we rank an article and determine where it will go in the app relative to other articles. Does it go towards the top of a section or towards the bottom? If the top, does it deserve featured treatment? Maybe it’s so topical it needs to be pushed to the Top page, which is reserved for only the most important stories of the moment.
Finally, diversification ensures there is a good mix of stories in each category. If there are 40 stories about guacamole and peas, here’s where we determine which to show and which to push to the background. If there’s a new development on a story, the update will push its way in and take prominence over an older story.
These are just details to give you context. The most amazing thing to me is when the app surfaces a “hidden gem” that I would not normally run across if I were using an RSS reader hard-coded to a collection of feeds, or a social network that is limited to news shared by my friends.
The best way to appreciate SmartNews as a discovery engine is to use it daily, but if you haven’t had a chance, here are a few more of my favorite Gems below:

While the Center for Medical Progress’ undercover video interviews with Planned Parenthood staffers may have been shocking, the representation of two points of view helped me see both sides of the issue. What was interesting was the Cosmopolitan article (a source I normally do not read) had the best measured rebuttal.

Much of the climate change news ends up in the Science category. As that story grows in relevance to us all, more publications dig into it. If you haven’t read this terrifying Rolling Stone piece, read it now.

Here’s an example of a developing story getting an update. ESPN reports that WWE is cutting its relationship with Hulk Hogan his comments that were offensive. People Magazine follows up with the story of his apology. Oh, also notice that the algorithm put both stories into the Entertain section.

As news of the killing of Cecil the Lion went viral, the algorithm was smart enough to surface a side of the story from a local Minnesota paper.

The screenshot above, more than any of the others, shows the freaky intelligence working behind the scenes. Like those times when an algorithmically generated playlist just nails the transition of one song into the next, drawing the causality between gun violence in the US to how such an environment might have prepared an off-duty soldier to do the right thing shows how a well-designed system can be greater than just the sum of its component parts.
Do you use SmartNews? Have you had the same experience? Send along some of your own Hidden Gems and I’ll add them to the gallery.




