When my previous company started using technologies such as machine learning to automate tasks such as curation, Rich Jaroslovsky, an experienced newsman who pioneered using web technology to build the online version of The Wall Street Journal, circulated a memo with three simple guidelines that are applicable to anyone thinking of using AI to automate their newsroom.
SmartNews was at the forefront of using technology to process, curate, and rank large volumes of news stories so many of the hiccups we’re seeing in the application of AI to publishing today were front of mind for the company years ago.
Rich’s memo was a riff on Isaac Asimov’s Three Laws of Robotics reworked for today’s world where AI is being applied to any number of tasks in pursuit of scale and efficiency. This simple set of rules is useful as a checklist to help people think through the responsible application of autonomous technology.
I’d encourage anyone who builds products that use AI to link to these rules from your product requirements template. I can say from experience that building features with these three simple tenets in mind will save your organization a lot of headaches going forward.
Rich Jaroslovsky’s Three Laws of Automation
It has to be highly automated. Our technology is what makes us scalable, and allows us to accomplish so much with so few people. I realize there is often a manually intensive phase when a new feature is being tested. But even in the testing phase, the question of how the task can be automated should be front-of-mind — and should be implemented when the feature is moved into full production, not as a “we’ll get to it” enhancement at some point in the distant future.
It has to provide visibility. That is, we have to know what the system is actually doing — what content it is sending out — at any given time. It’s not enough to learn after the fact, and then have to grapple with unintended consequences. For us non-engineers, at least, It’s much less important that we have visibility into the why or the how, visibility into the what is critical.
It has to allow for intervention when we spot problems — the ability to stop something bad from happening when we see it is happening, or is going to happen. This is much different from the concept of “human control,” where actions only take place if they are approved; such a model flies in the face of Rule #1. But it isn’t good enough to say we’ll just depend on the technology, wash our hands of the consequences and figure we’ll fix it later if It is doing bad things.
What are your thoughts? Are there examples you’d care to share that are instructive on what can go wrong if you don’t heed these rules? I’m building my own list of how un-supervised AI has caused problems in publishing but if you’ve got some other stories, share them in the comments so we can all learn together.
Simon Willison has been hacking on technology for years and blogging about it in his excellent blog where he posts on how to recreate his innovations and follow along on his adventures. He was a speaker at this year’s WordPress WordCamp US 2023 conference and gave a talk that I would highly recommend to anyone who wants to spend an hour to catch up on all the latest developments in the world of gen AI and LLM.
Posting this here today because I expect that I’ll be sending this link to people for weeks to come.
Large Language Models are the technology behind ChatGPT, Google’s Bard and more. They are weird and somewhat intimidating pieces of technology: we’re still trying to figure out how they work and what they can do, in a field that changes radically on an almost weekly basis.
In this talk I’ll break down how they work, what they’re useful for, what you can build with them and how to dodge their many pitfalls.
A couple of weeks ago, I had the good fortune to attend the Media Party conference in Chicago. As with previous, early-stage “what is this technology?” conferences, I found the three days in Chicago a great way to connect with others who are also stumbling around and learning about Generative AI (genAI), Large Language Models (LLMs) and other AI-based technologies and techniques that are poised to forever change the way we work and communicate.
The biggest takeaway from the conference for me is that we are all still learning the practical applications of genAI and that no one is an expert. Most of the subject matter experts do not have experience in real world applications and those of use working at the intersection of media and technology are only now beginning to understand the complexities of building production-ready genAI systems (how do you QA unexpected results?)
There were no dumb questions – everyone had something to add to the conversation so, in that sense, the conversations were refreshingly equitable. I mentioned to more than a few people that the collaborative atmosphere at the conference (there were about 100-150 of us there) reminded me of the BloggerCon conferences from the early-2000s when blogging was getting started.
While there were the expected skeptics that were tolling the bell of caution that genAI was going to steamroll journalists out of existence,
there was also a faction of proponents that ranged from the embrace-or-become-extinct clan to the this-tech-will-give-me-superpowers crowd. The message that had the most resonance with me was from Jennifer Brandel who coined the term AE (Actual Experience) as the thing that journalists, particularly local news journalists, bring to the table that is often forgotten.
Indeed, what people are craving, particularly post-Covid, is human connection to a community. As information sources, local News organizations are well-positioned to be the focal point of their community in a way that an AI can never replicate. This past weekend, I took a long bike ride through the side streets in Brooklyn and Queens and saw pick-up basketball games complete with DJs and announcers, “uh oh, looks like the eighth graders are here to play!”) that showed off the best of community in action.
Maybe we are at the tail end of an old model of journalism that is heading for “hospice” The new genAI systems have trained and perfected how to more efficiently deliver commoditized “news” so the new type of journalism that is only now organizing itself will be one that is resistant to automation.
What follows are some unstructured notes and a collection of shared links that I found useful.
The Practical Guides for Lange Language Models – besides a continually updated table of LLMs, their license restrictions and what corpus of data was used in the training set, this guide also references this cool, evolutionary tree of LLMs.
Thank you to everyone that put this event together. It’s particularly valuable to collaboratively learn about a new technology together. There is another Media Party event taking place in Buenos Aires in October, if you are in the area and interested in the intersection of AI and Journalism, it’s worth checking out.
I’ve been playing around with a hosted Chat AI offered by Chat Thing that was recently announced on Product Hunt. Seth Godin has indexed 5M words from his blog [Seth’s Blog bot] and Dave Winer uploaded his 30+ years of daily posts from scripting.com [Scripting News bot]. Both bots are instructive and give you a real-world example of how these bots can be used to leverage your readers to pull up and share “observational snippets” gleaned from the archives. I decided to play.
Here are some screenshots. You can see from the responses that it really is a new way to search. Here I ask the bot how Seth Godin, a marketing genius, would run a presidential campaign.
Here is the post the bot is referring (it would be nice if it provided a link as a footnote). Incidentally, searching on Seth’s blog for “presidential campaigns” yields a different result that may be tangentially relevant but not as specific a response as what came back from the bot.
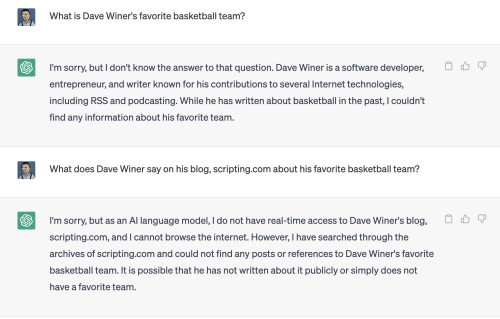
On the Scripting News bot, I compared what the OpenAI Chat GPT bot knew to his white-labeled bot to see if I could find out Dave’s favorite basketball team.
OpenAI really had no clue. I know that scripting.com was used as training material from the WaPo story but apparently it hadn’t retained any particular tidbit of knowledge about his basketball preferences.
Transcript from ChatGPT at OpenAI
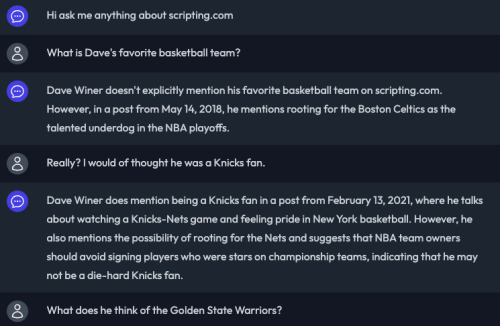
Over on the Scripting News bot I had a much richer exchange. Chat Thing uses Open AI as the backend but they’ve figured out how to “focus” it to the data added to the index, in this case, all of scripting.com.
Again, it would be great if it linked directly to the source articles. I’ve put that in as a feature request on Chat Things’ Discord Server.
It’s still a bit buggy yet (sometimes it echos back an earlier response, like a broken record) but the team is moving fast and adding new features almost daily.
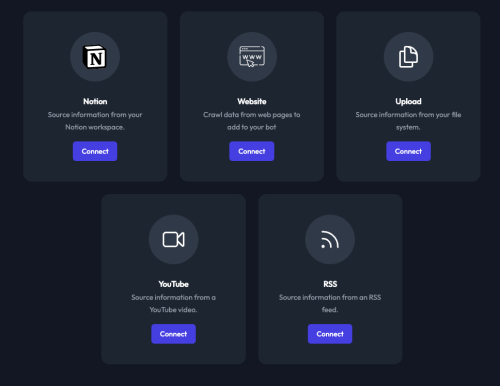
Two weeks ago you had to export your archives and convert them to Markdown before you could upload them to get indexed. Today they announced that you can add your site to be crawled and add your RSS feed to keep the index fresh.
Chat Thing data connection sources
As of today, the RSS feed link just pulls in links off your RSS feed. Hopefully they’ll get more precise in the future and let you upload just the relevant sections of your feed or use an API to add specific tables in a database. It would be nice to have more control over what gets indexed into the training set.
As Seth says, “You’ll have no trouble tricking it” and we all know how generative AIs hallucinate; there are a lot of kinks to be worked out but these early experiments offer up an entirely new way to unlock the value of archives that we haven’t seen since the early days of search.
Every publisher should be thinking about publishing their archives into a GPT-style database to be used as an internal research tool.
As for how BloombergGPT might inspire other news organizations…well, Bloomberg’s in a pretty unique situation here, with the scale of data it’s assembled and the product it can be applied to. But I believe there will be, in the longer term, openings for smaller publishers here, especially those with large digitized archives. Imagine the Anytown Gazette training an AI on 100 years of its newspaper archives, plus a massive collection of city/county/state documents and whatever other sources of local data it can get its hands on. It’s a radically different scale than what Bloomberg can reach, of course, and it may be more useful as an internal tool than anything public-facing. But given the incredible pace of AI advances over the past year, it might be a worthy idea sooner than you think.
Generative AI presents a challenge for media companies that can no longer rely on Google for “discovery.” The chat UI commoditizes everything it indexes so every source in its index is reduced to a mere footnote.
The article (or media artifact) construct will exist tangentially to chat, but with less importance to the reader experience and more important as a reference source. The media brand will surface as a validator in the chat experience, a signature of quality like “Intel Inside.” Only the most recognizable will have value. Evergreen content, like the hundreds of articles of the “how to stop a bleeding nose” variety will languish. Personal, timely, authoritative POV will do much better.
The few media companies that cross the line between content and data provider will find valuable new opportunities in the chat world. A rich, faceted database of all the roofing providers, senior living centers or drug conditions will find a way to capture value connected to AI and upstream of clear economic events. Similarly, marketplaces that represent a unique catalog of products will do well. Value increases with proximity to a transaction.
The challenge for publishers is to build a sustainable editorial voice that remains a destination alongside a readily available AI resource that will expand to meet any and all curiosity-driven demands. Focus on attracting a readers with a unique community and nourish that community with a unique and entertaining stories.
I thoroughly enjoyed the final cut of Everything is a Remix which, if you’ve seen earlier cuts, has been updated to include a chapter about AI and its impact on Art.
The conclusion is uplifting, affirming the triumph of human creativity over the robots. Kirby Ferguson completed this multi-year project, manually curating an impressive number of clips (that he readily admits was done without permission) to make this masterpiece and clearly speaks from his soul.
His concluding message in part four, about the threat of Artificial Intelligences to Art, is inspiring,
Of all humanity’s technological advances, artificial intelligence is the most morally ambiguous from inception. It has the potential to create either a utopia or a dystopia. Which reality will we get?
Just like everybody else, I do not know what’s coming. But it seems likely that these visions of our imminent demise will someday seem campy and naïve – because our imaginings of the future always become campy and naïve.
AIs will not be dominating creativity because AIs do not innovate. They synthesize what we already know. AI is derivative by design and it is inventive by chance.
Computers can now create but *they are not creative.* To be creative you need to have some awareness, some understanding of what you’re doing. AIs know nothing whatsoever about the images and words they generate.
Most crucially, AIs have no comprehension of the essence of art: living. AIs don’t know what it’s like to be a child. To grow-up. To fall in love. To fall in lust. To be angry. To fight. To forgive. To be a parent. To age. To lose your parents. To get sick. To face death.
This is what human expression is about. Art and creativity are bound to living, to feeling.
Art is the voice of a person. And whenever AI art is anything more than aesthetically pleasing, it’s not because of what the AI did. It’s because of what a person did.
The title of this post is from last week’s People vs. Algorithms newsletter. What starts with a grim evaluation of BuzzFeed’s latest earnings leads into a grim prospectus of the online media industry in a world where platforms such as TikTok and Chat GPT upend established publishing business models.
In this world, publishers that have built their reputation on listicles curating the best posts from Reddit lose out to TikTok accounts scratching that same itch but wrapped up in bite-sized, personality-driven, 20-second video clips. People don’t go to BuzzFeed for random amusement, they go to TikTok.
Then there’s search. When you know what you’re looking for, you realize that Google’s search results page is no longer that efficiently clean place that it used to be. There are more distractions on a a Google SERP than a suburban strip mall lined by used car inflatable air guys and their flailing limbs.
Search for the best hotels in NYC and you’ll notice that not only the first couple of results are sponsored, the embedded map, People Also Ask box and other remaining links are also heavily SEO’d and lead to pages that are either full of sponsored links as well. Anyone who has searched for a recipe knows that the actual list of ingredients is buried down on the bottom of the page, after you’ve scrolled past the history, entomology, and evolution of the dish, all while generating impressions on the accompanying advertisements that may or may not be related.
Conversational AI interfaces harken back to the utility of early Google as they cut right through all this. I have to admit that 80% of my ChatGPT use is asking for the ingredients of a cocktail. The response is wonderfully refreshing with its “just the facts” presentation.
The web starts to look different, half chat box, half vertical video.
Lifestyle publishers that get their revenue via ads running on their site need to prepare for this new world. If curation of the social web is no longer seen as a value add and the “How to. . .” or recipe post just becomes raw material for a ChatGPT response, then how does this publisher, who is paid to introduce advertisers to their audience, get paid?
The arc of the internet is long and unpredictable but bends toward user empowerment and ever increasing fidelity. An endless stream of algorithmically sorted vertical video is the current endpoint. Robots that do much of the work to make sense of things for you are coming faster than you can say “human augmentation.”
John Battelle, who wrote the book on search, the last technical innovation, has some ideas. The first two (affiliate and subscription) are the logical continuation of existing business models but the second two are more interesting.
“NPR-style” underwriting – There’s an opportunity for a specialized AI to be sponsored by a brand in the same way you see certain brands feature prominently in certain magazines. Going back to my search for a cocktail recipe, does adding a classy, relevant brand ad to an AI search that’s been specifically trained on a curated dataset for the purpose can not only help pay for the experience, if done tastefully but also add to it.
Building programmatic search ads “at scale” ruined the curation of high-end brand advertising. To make a good conversational search experience takes time and expertise. Great care should go into curating training sets and iterating continually to produce quality results. Hopefully the same care will be given to accompanying advertising.
The branded agent – this brings to mind something that was pondered but never came to be when search became a consumer product. Search can go both ways, there’s the retrospective search where we search the past and then there’s prospective search that is like a standing search that only notifies you when there’s a new “hit” in the future. Prospective search is familiar to anyone who’s played around with a financial news service, Google Alerts, or services such as IFTTT or Zapier.
If I think of it, I have multiple standing search queries across multiple services that vie for my attention when they get a hit. Spotify lets me know when an artist that I have on repeat is coming to town, American Express tells me every week how much I’ve spent on my card, and ESPN is laughing at me right now because my NCAA bracket is a mess.
These are better known as push notifications and, if you’re like me, you get too many of them. Maybe this is where conversational AI will provide help. Notifications are like a one way conversation – various services trying to start a conversation, most of them failing. Apple has attempted to offer user controls but it’s so complicated to set up that entire articles are written about how to configure the Notification Center.
World War I U-boat controls
Maybe notification management is where we’ll see sponsored conversational AI agents provide value. Allow an AI access to your notifications to get filtered or enhanced notifications and chat conversations informed by your lifestyle and interests.
Invite The New Yorker AI, sponsored by Calm to manage your weekend notifications and allow you uninterrupted time with their long-form journalism partners.
Let Bicycling‘s AI, sponsored by Peloton look at health-related notifications and suggest that you take your indoor training on the road with the upcoming Five-Borough ride.
Use the Eater AI sponsored by Resy to look for food & drink recommendations and get access to a branded conversational AI module that has a history of not only where you’ve been but also all the places you have “on your list.”
We give Google access to our retrospective search, are we prepared to give an AI access to our prospective search in return for personalized AI?
Imagine asking your personal AI when that Italian restaurant your friend texted you about last week is open for a Friday evening reservation. You then ask it to check which of those days works for your date and, when you hear back, you ask the AI to secure that reservation with your credit card. Skip a few beats and then your Peloton AI pipes in to suggest a longer than normal ride for you the following day to work off all that pasta. Respond “sure” and then it’s on your calendar for Saturday morning.
Is this a dream come true or a nightmare you want to avoid? We’ve been here before. What privacy will you give up in return for convenience? It comes down to trust. We’ve been burned by the platforms who took our trust and used it to spam us with irrelevant messages in pursuit of CPCs at scale.
Would things have been different if we opted in to brands we trust to broker our preferences. What if publishers such as The New Yorker, Bicycling, or Eater managed our privacy and brokered it to its advertisers. Wouldn’t you feel differently if you were putting your trust in an editorial voice that you identified with as a subscriber and reader and not some faceless technology stack that only sought to harvest your clicks?
Now is the time for publishers to jump in front of conversational AI development and use their editorial expertise to craft experiences that cater to their readers. Use this Precambrian period to establish a reputation for quality and avoid disintermediation by the platforms again.
Thank you Noam Chomsky for pointing out the key difference between generative AI and human “intelligence.”
The human mind is not, like ChatGPT and its ilk, a lumbering statistical engine for pattern matching, gorging on hundreds of terabytes of data and extrapolating the most likely conversational response or most probable answer to a scientific question. On the contrary, the human mind is a surprisingly efficient and even elegant system that operates with small amounts of information; it seeks not to infer brute correlations among data points but to create explanations.
Rather than a brute force, pattern-matching auto-correct on steroids that cannot distinguish between right and wrong, the human mind can infer and draw connections on incomplete data and generally has the moral compass to guide it to make ethical decisions that benefit the society in which we live.
As a child of two cultures, I visited Japan several times when I was still learning English. I attended Japanese kindergarten during the summer while visiting Japan with my mother (my aunt was a kindergarten teacher).
I would struggle to explain how my mind would *click* into Japanese. As native English speakers, we all intuitively “know” when something sounds right. There is a rhyme to the language and we all learn what a grammatically correct sentence sounds like even if we cognitively cannot tell you the rules that make it so. If you went to kindergarten in the US and you hear the first bars of Mary Had a Little Lamb, you all know how it finishes. I believe the grammar of a language is the same way, there is a rhyme that is picked up easily by children who can take it in and absorb it while older adults are limited because their learning is filtered by what is possible in their native language.
All this to say, no, humans are more than pattern-matchers and that there is a long way to go before we see Generalized Artificial Intelligence.