When I worked at Yahoo it was at the height of a cultural trend called Web 2.0. The fashion was to put stickers of various startups all over the front of your laptop so people could see how hip you were. I was running into many interesting people so I took a different approach and asked them to sign my laptop with a sharpie instead.
When the laptop started to give out, before handing it back Yahoo IT and took a snapshot for posterity.
My web 2.0 laptop
Here are some of the names. Click on the photo above to go to the Flickr page that has them tagged.
Rafat Ali Stowe Boyd Nick Denton Caterina Fake David Filo David Jacobs Bradley Horowitz Guy Kawasaki Ross Mayfield Richard MacManus Dave McClure Matt Mullenweg Ray Ozzie Greg Reinacker Doc Searls Deborah Schultz Kathy Sierra Bruce Sterling Chris Tolles David Weinberger Dave Winer Niklas Zennström
Lane Becker is an optimist. He was co-author of a NY Times best seller Get Lucky and his twitter bio says, “You’re pretty.”
I got to know Lane during the early days of blogging and he was one of those ever-cheerful folks that helpfully pointed out the way forward, never talking down at you or taking privilege from his influence in the community. A true community builder, he lead by inclusion. Get Satisfaction, the distributed support network he built with Thor Muller was a reflection of his spirit.
Many aspects of the service were cutting edge and advanced concepts we take for grated today. I invited Lane to speak at the third segment of the Better Builder’s Bureau to talk about the early days and over the course of an hour he weaves a tale of Web 2.0 history that takes you right back to those times where,
SaaS was not a thing
Social Businesses didn’t exist
Web sites were a series of static pages, not interactive “apps”
So sit back and relax and take a trip back and remember what it was like back in 2007.
Highlights/Notes
You just have to be slightly ahead of the curve to succeed, “Silicon Valley is about the relentless present. The goal is to be right, right now.” People who are too far off in the future are often failures. It’s as much about timing as everything else.
Timing in Silicon ValleyThe origin story of the word, blog
e-commerce as performance art and the lightbulb moment
Flashlight forums and “beam shots” as the model of an engaged online community that is independent of a company. The existence of these communities convinced Lane that there was a business around community sites around company products, “stuff could be a thing that connected people.”
The Beam Shot community
Get Satisfaction as a place for a broader conversation, one that not only includes a channel for problem resolution but also hosts threads about ideas and praise. Customer Service without companies.
Questions, Problems, Ideas, and Praise
Google Alerts hack that got them the attention of every single marketing executive, “we had accidentally created a direct line to every marketing person on the planet around the problems with their product that were key and important for them in that moment. This turns out to be key in the growth of our organization.”
The Google Alerts hack
Help tab came out of a specific set of circumstances. Product Managers are the ones that can synthesize multiple inputs and create features as solutions for these situations. How do we solve the problem of how to “get on every page” while still staying true to the product’s personality and soul.
A good PM has a gut instinct for the soul of their product
Good guerrilla marketing does not equal a good business plan. Lane wishes he had just written a better help ticket system. That would have given him the runway to innovate.
The future markets very well but the present sells.
Social did change business. It is reality today but the specific Get Satisfaction solution “bounced off the answer but it wasn’t the answer”
“We were directionally right but specifically wrong”
Code for America No tensions around advertising. You don’t need to sell government as a service. This allows you to make wildly different choices in product design. No need for customer growth, city governments can tell you where everyone lives and how to get in touch with them. More important is to reach and get responses from the population. You cannot have a target market and optimize just for that.
Differences in designing product for government
Government policy is waterfall development. All the argument comes up front. What would it look like if they went agile, that power and authority comes from execution, not elective office or budget.
How technology will change government
City of Oakland Record Trac shows speed and status of Public Information requests. By making public each department’s response time public the service has worked so well that each department uses Record Track instead of internal channels. The project was so successful that Code for America is spinning Record Trac off as a separate company.
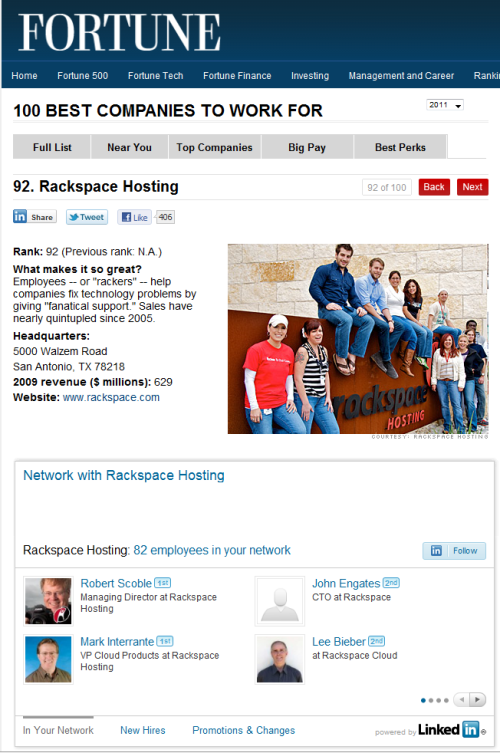
Congratulations to whomever is turning up the heat over at LinkedIn. It’s been just over a year since they opened up their API and now we’re really starting to see the fruits of this effort. The latest integration with Fortune on their 100 Best Companies to Work For demonstrates how a professional social network can add value to a web publication. Browse through this list while logged into LinkedIn and on each companies profile page you’ll see a list of any of your connections that work at that company. It’s like the old Six Degrees game but with a purpose. You’ll be surprised at who shows up (Hi Mark!)
The hackday-inspired Resume Builder takes the data you’ve already added to your profile and gives you a series of templates for a cleaner output in PDF format suitable for sending via email or printing.
LinkedIn Share buttons that you can add to your site works just like the Facebook Like button, crowd sourcing the curation of the web.
Integration with OneSource iSell product to combine their “triggers” with to help Sales teams connect with their prospects through existing relationships.
Bump integration making connecting via LinkedIn easier than ever.
A Microsoft Outlook social connector to add LinkedIn profile information to your email and contacts.
Ribbit Mobile integration resulting in a product they call Mobile Caller ID 2.0. It installs on your mobile phone (sorry, UK and US numbers only) and does a dynamic lookup on incoming numbers to see if LinkedIn (or other connected networks) has any information about who is calling and what they have recently shared on the social web.
LinkedIn Tweets, an application that has a cool, somewhat hidden feature, that creates a twitter list of all your LinkedIn connections that have twitter accounts and (and here’s the cool thing) will add new members to that list automatically as you add new connections on LinkedIn.
LinkedIn Tweets
All this is on top of heaps of new features they’ve added to the site including the faceted search UI and the ability to customize your profile to name just a few. Really stellar work.
LinkedIn 2009
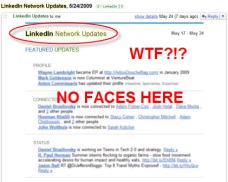
Finally, what prompted this whole post to begin with, and I’m not sure how widespread these emails are, was this customized visual that summarized who in your network has changed jobs. What a contrast to the old, text-heavy, anti-social LinkedIn of 2009 where “connections go to die” – the new LinkedIn is much more vibrant and connected with the world outside. Looks like they’ve taken Dave McClure’s advise from over a year and a half ago when he berated them and screamed, it’s all about the faces.
Before Christmas I posted about the possible break-up of clouds. For the past 5 years or so, the usual suspects such as Yahoo, and Google, and more recently Facebook and a re-vitalized AOL have been sucking up smaller collectives of socially active sites in search of rich pockets of user engagement.
Clouds are an apt metaphor because we’re reaching a time when some of these large, ad-supported clouds are getting too heavy and are starting to look for ways to offload sites which don’t monetize by either shutting them down or selling them off. Think of the threat late last year to shut down delicious.com as the first cloudburst which resulted in a shower of users taking their data fleeing that cloud in search of a new home.
FourSquare announced that they’ve added photo uploads to venues for their check-in service. This leads me to ask, why they make me upload new photos for places I’ve been. I’ve got year’s worth GPS-encoded of photos sitting on Flickr. 4Sq can cross-reference the location and time stamp on my photos, match it up with my check-in history and get a bunch of photos for venues right away.
flickr map
Why doesn’t FourSquare let me push in photos from my Flickr account? Are they worried about mis-matches? They could use a little Machine Tag foo and let me select which photos to link to a location. Most likely it’s just a pain to build a connector. Better to start over and build up your own dataset right? It’s cleaner, more current, and they avoid the legal hassles of having to partner with Yahoo, much better to own the data right?
The nagging problem about tying venue photos to images hosted on another cloud is that it opens 4Sq up to dependencies. Do they really want to rely on flickr to host their venue photos? Not only do they lose editorial control over those photos and if a photo turns out to be offensive or violates some kind of copyright, who is at fault? FourSquare? Flickr? Yahoo? Most likely you’re going to have to cut some kind of deal which means the Biz Dev guys have to get involved. Contracts, SLAs, a big pain which limits your options in the future.
Tim O’Reilly posted a while back that the tendency of Web 2.0 companies is to monopolize their vertical to secure control and cut dependencies:
If big companies get too protective of their data and the legal hassles around free exchange of data make it harder for consumers to connect their data in these clouds together, we’ll all be forced to either throw our lot into a single cloud which gives us the most complete suite of connected services (facebook or google) or risk tenuous connections in search of our own, best-of-breed solution.
Consider the alternative. Consumers hosting their own data. Check out Pogoplug, this neat little service that sticks an ethernet port into the back of a external hard drive that sits on your desk and connects directly to the Internet, turning that hard drive into your own little “private cloud.”
Pogpplug
What if your Pogoplug held all your photos, blog posts, status updates, scrobbling history, and other lifestream detrius? You can stream it out the back and use it to feed flickr, facebook, and your other favorite caching layers where people can view it. Again, I’m not suggesting you serve up to the internet at large via this little box on your desk, that would be madness. Just have all or originals there and use your favorite social network, photo/video/link sharing service as the copy that feeds your fans. The important point is that the source, the seed for all these large clouds to which you syndicate, is under your control.
If a shiny new photo-sharing startup catches your eye you can give it a shot by forking off a feed of your photos to it’s API endpoint and get started with a collection of your own stuff on their service. No need to export from old photo-sharing site to this new one, you’ve got the raw data sitting on your “private cloud” and can start with a clean copy of your entire archive.
For further reading, there’s a healthy thread between Jeffery Zeldman, Tom Henrich, Jeff Croft, Tantek Çelik, Kevin Marks, Glenda Bautista, Andy Rutledge and others about the methods, and even necessity of hosting your own data. Tantek, for one, has put his money where his mouth is and is busy writing software and pushing this vision.
I’m building a solution, bit by bit. It’s certainly incomplete, and with rough edges (Jeffrey has pointed out plenty of the areas that need work), but iteratively improving as I find time and inspiration to work on it.
I’d rather host my data and live with such awkwardness in the open than be a sharecropper on so many beautiful social content farms.
This is what I mean by “own your data”. Your site should be the source and hub for everything you post online. This doesn’t exist yet, it’s a forward looking vision, and I and others are hard at work building it. It’s the future of the indie web.
Warranted or not, the great delicious.com shutdown scare of December 2010 teaches us all an important lesson about the sustainability of cloud services.
If you’re not paying for a product, you are the product.
This quote paraphrased from blue_beetle on metafilter is very apt. Companies that offer free services to their users do so in the hopes they make a return on their investment to run a service. If you’re not paying for a subscription to use a service then you’re paying with your perceived attention through advertising. Let’s ignore the fact that there are multiple ways that Yahoo could have used the delicious corpus of annotated links to increase value across their network. The fact is nothing comes for free and if the owner can’t figure out how, they are within their rights to pull the plug. We all need to be aware of this fact in the same way that we need to read the fine print on any free checking or 0% financing deal we get in the mail.
The old adage still applies. Make sure that everything you put in you can take back out. Delicious has an export feature built into their API so that if you every get twitchy, you can grab your data and take it elsewhere. I would never put my blog onto a platform, hosted or not, that wouldn’t let me pull it back out. Beware of one-way streets.
So all this moving about and looking for a new home for your stuff brings up an old debate. Should you host your own data?
In the past this was not a realistic option for most. The costs and complexity of setting up your own domain and software was far to difficult and expensive. But it’s worth revisiting. The cost of hosting your own server has come down dramatically. Maybe it’s time has come when we can push things to the edge. Stephen Hay challenges us to ask why not:
What if we flipped this all on its head? What if we hosted our own data, and provided APIs for all these webapps so that they can use our data? … So instead of having our own websites aggregate our own data from other people’s websites, we’ll let other people use the data from our own websites. Photos, meaningfully tagged, can be pulled in by Flickr via our own personal API, if you will. We provide the structured data, Flickr provides the functionality. The sharing. The social. Why not?
Imagine a world where I pay $100/year to host all my stuff (blog posts, bookmarks, status updates, photos, videos, etc) which can offset that by services paying me for access to that content. Each service can “pay” me by providing a service that plays to their strength:
Yahoo pays me for access to my hosted photos with the collective photo tagging and geo-location tools on flickr.
Google pays me for access to my blog by sending me traffic and offering ad rev share.
Facebook pays me for access to a feed of my posts and likes by offering a social layer of my friends.
Twitter pays me for access to a feed of my status updates with distribution.
For the cost of a single month’s cable TV bill I now can pick and chose which service I use and turn off and on each one at will without fear of migration. Today I “host” my money at a bank and point all my monthly bills to that bank, why can’t I do the same with my digital savings? Bundling blog software with a hosting account was a business I helped set up at Six Apart. Adding email, photos, videos, and bookmarks and putting a nice user-friendly front end onto it could be a real opportunity for an clever hosting provider.
One final thought. If each of us hosts our own data, companies would be much more likely to standardize how they integrate with our data and make it easier to mix and match datasets. It’ll be in their interest to offer the best tools for data to flow in and services to flow out. With users and data aggregating into just a handful of large players, it is not in a company’s interest to offer these tools, it’s better for them to lock users and data up to prevent loss of audience and attention used to monetize those users.
That’s a topic for the next another post (which is posted here)
Long post by Tim O’Reilly on the current state of the Internet as an Operating System. Many key developments that see this idea coming together and Tim connects the dots in a compelling way to complete the picture. The key piece for me is Social. The Internet OS still does not usefully recognize that we have multiple social graphs that depend upon application and context. Current solutions such as Facebook Connect currently assume a universal “friend’s list” which doesn’t address this subtlety.
Whoever cracks this code, providing frameworks that make it possible for applications to be functionally social without being socially promiscuous, will win. Platform providers are in a good position to solve this problem once, so that users don’t have to give credentials to a larger and larger pool of application providers, with little assurance that the data they provide won’t be misused. (Emphasis mine).
This is a key problem that needs to be solved. Location-based services and mobile devices are pieces of the puzzle but more synapses are needed to make it work effortlessly.
It’s hard to wrap up a major conference, especially when you didn’t attend, but viewing things from a distance sometimes helps because only the loudest messages make it all the way over.
Before the conference even started, Fred Wilson threw out a one-liner that got people thinking. He called it the Golden Triangle.
The three current big megatrends in the web/tech sector are mobile, social, and real-time.
To Fred, the vectors between each of these points on his triangle represented the biggest opportunities over the next few years and where he, as a technology VC, was going to focus his attention.
Ross Mayfield, his line from the first Web 2.0 conference is still relevant, added Geo to Fred’s Triangle and posted his virtual napkin up on flickr.
The importance of Geo cannot be ignored as the most obvious (and easiest) way to add context to information which is being harvested and sent our way in increasingly alarming rates. We talk about a world in which there are 1 billion mobile devices. Imagine what happens when each of these gets a camera, gps, and bluetooth sensor and an IP connection to pull in real-time updates. Adds a new dimension to Right Here, Right Now.
So while HTML Page Indexers of yore were failing at finding us the best Chinese in Helsinki or plumber in London, Social Discovery became the new nectar. Facebook leads to FriendFeed leads to Twitter and now our capacity to consume and process has overloaded. Groups, Hashtags, Lists, Folders, call them what you will but this manual organization of streams is beginning to feel like e-mail folder management all over again. The Googles and Microsofts have added the Twitter firehose to their indexes but somehow I don’t see that as solving the problem unless they can filter on your social connections as well (rumor has it Google Profiles are about to play a much more important role Google Social Search is now live).
Which brings us to Social Filters.
Marshall Kirkpatrick has been following this topic for a long time. He bangs the Social Filter drum again in a post about Facebook’s News Feed redesign,
Someday social networking is going to be like the telephone. Today you can’t send messages from Facebook to people on MySpace or LinkedIn but that isn’t going to last forever. Just as you can call someone who uses T-Mobile from your Sprint phone, someday sharing and messaging between online social networks will be a given.
How will social networks retain users then? Why stick with Facebook when some smaller service offers a decentralized social networking service outside of Facebook’s control but still tied into your friends on Facebook and elsewhere?
These services will someday have to compete on user experience, when they no longer have your social connections locked-in. The service that does the best job filtering up the most important information you have coming your way will likely be the service you stick with. That’s going to be a key area of competition between social networks.
Yes, it’s no longer about who “owns” the social graph – it’s who provides the best services on top of a shared graph. Someone mentioned that Tim Berners Lee said at the conference that AOL was to WWW as Facebook is to distributed social networks. Just as we thought it silly that AOL wanted to put it’s famous wall around the internet, we may also look back in amazement thinking that anyone could have the audacity to think they could own the world’s social address book.
There is a race on right now to own the social graph. But we must ask whether this service is so fundamental that it needs to be open to all.
It’s easy to forget that only 15 years ago, email was as fragmented as social networking is today, with hundreds of incompatible email systems joined by fragile and congested gateways. One of those systems – internet RFC 822 email – became the gold standard for interchange.
We expect to see similar standardization in key internet utilities and subsystems. Vendors who are competing with a winner-takes-all mindset would be advised to join together to enable systems built from the best-of-breed data subsystems of cooperating companies.
Bringing it all together you can almost hear the synapses of the global brain achieve self-awareness. Not only are we moving to a web of sensors feeding real-time data into the grid, we are annotating it by injecting bits of human commentary and behaviors across an increasingly distributed social graph.
A phone in one corner of the world sends off a snapshot which is immediately re-tweeted via the world’s largest telephone tree. More reasoned minds pick up the samples, turn it over and examine it and later conclude that no, the calculated mass of the balloon could in fact not hold a small boy aloft – rumor refuted! Lesson learned and the network becomes a little smarter, more skeptical, less knee-jerk adolescent. Sentient if you will.
The pieces are in place, the machines are warmed up. It was fun while it lasted but it’s time to put Failblog aside and see if we can move on to tackle bigger problems. O’Reilly and Battelle wrap up with their call to arms,
2009 marks a pivot point in the history of the Web. It’s time to leverage the true power of the platform we’ve built. The Web is no longer an industry unto itself – the Web is now the world.
I heard this line somewhere but can’t attribute it to anyone. Did a search on Google, Yahoo, and even Bing and didn’t find any mention of it either. In an increasingly interconnected world, when one social network is connected with another, if you can’t share something, does it count?
So I’m really excited because I scored a free pass to this week’s Web 2.0 Summit based on a comment I left on John Battelle’s blog where he asked his readers for questions for executives he is going to interview on stage. My question was for Paul Otellini, CEO of Intel:
Do you forsee a time when Intel will embed social features into its hardware? Microsoft tied it’s activation to Windows activation. Would Intel ever offer the ability for users on Facebook and other social networks be able to uniquely identify itself to a social graph and the associated permissions via the Intel chip?
Besides the v-chip (which embedded the parental rating system into televisions) and the Windows activation mentioned above, are there any other instances where hardware embedded a social action or social rating into hardware?