While it may be technically true, I’m not a big fan of Spokeo’s new positioning.

a blog by Ian Kennedy
While it may be technically true, I’m not a big fan of Spokeo’s new positioning.
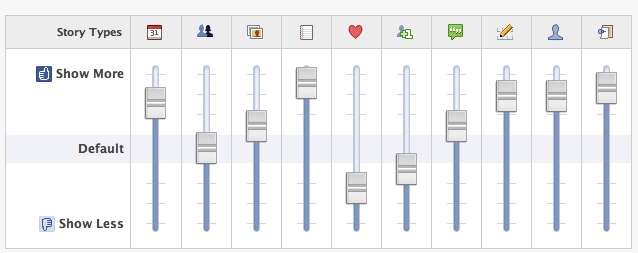
With over 175M users, Facebook has famously opened up for distribution of marketing messages from businesses, brands, and celebrities. My wife Tivo’d an appearence by Mark Zuckerberg on Oprah introducing it to its mainstream audience and most surely to any brand marketer interested in reaching Oprah’s audience. If Jason Calcanis puts the value of a slot on twitter’s suggested users at $250,000, then a slot on any Facebook featured user page has got to be multiples of that.
If you hit Facebook in a logged out state, look for the, “To create a page for a celebrity, band or business, click here.” link and this is what you’ll see. No more fan pages – social influence is now officially reserved and will most likely be for sale.

Thank you Daniela for pointing me to Clay Shirky’s keynote at Web 2.0 Expo last week in New York. In it, Clay gives a talk on Social Networks, Lifestreaming, and Privacy. It’s a timely talk as lifestreams go mainstream. I’m really happy to see someone like Clay talking about the social impacts of lifestreaming and the crudeness of the tools we have to manage them.
Some quotes to give context.
The problem is that “managing” your privacy settings is an unnatural act. It’s not something that anyone is good at setting up or doing. Prior to the present day, the only person any of us could name that had anything you could call privacy preferences was Gretta Garbo. Privacy is a way of managing information flow.
The inefficiency of information flow wasn’t a bug, it was a feature. The guarantor of privacy was simply that it was difficult to say things in public.
How do you control what you publish so that simple updates such as the one used in Clay’s talk, that you’ve gone from having a relationship to now being “single” goes to the folks you want to know without being blasted out to everyone connected to you via your lifestream? Clay’s point is that the manual settings to control privacy are not intuitive and all it takes is one slip up to cause irreversible damage.

On the flip side, we’ve all heard that everyone is famous for 15 people. It’s now trivial to share your online activity across multiple services so that anyone and everyone can tune into your lifestream and keep up with every bookmark, blog post, photo, and status message you ever make. Keeping up with your friends is as easy as clicking a subscribe or add contact button.
It’s no longer the effort of publishing that is the filter. First with blogs and now with lifestreaming, publishing is so easy that we now have too much to process. As I said back in April, the new challenge is coming up with the right filter. Once you’ve pulled together all your personal and professional contacts into a single feed, how do you make sense of it all? Just as I used to worry about missing an important post that lay buried in my collected RSS subscriptions, how do you make sure you catch what is going to be important without having to spend time getting distracted by the tangential stuff that comes along for the ride?
Contexts are going to be the key inputs. Are you at your desk? Are you looking at your feeds via a dedicated client such as a feedreader or are you looking at a thin sliver via something like Gmail webclips? Maybe you’re looking at a particular post and want to see if any of your work colleagues have posted something or left a comment. Are you on a phone with some down time between meetings? Or are you disconnected from the web on a cross-country flight and want to catch up on industry news?
All these contexts can be accommodated but they need to read from the same source or be synchronized in some way to keep you from reading the same thing twice. Even better, if something comes up more than once in different contexts, that could be a signal telling you that you really should read post you’ve passed by in another context.
MyBlogLog, Friendfeed, and others are building the master feed – I’d love to hear from others on what types of contextual filters can be built on top of those feeds to goose the relevance.
 Image via CrunchBase
Image via CrunchBase outside.in, the local news site co-founded by geographer-historian Steven Johnson, launched a service called Radar which claims to feed you news from within 1,000 feet of your stated location. Similar to the other hyper-local services like EveryBlock and Topix, their service parses blogs and other social media for stories tied to a specific location.
outside.in also added GeoToolkit for publishers that want to geo-tag their feeds and take advantage of outside.in distribution. For users, they’ve synched with Yahoo’s FireEagle platform to automate updating of your location. The “news within 1,000 feet” is a compelling promise and hopefully it will generate enough interest in the service so they can reach critical mass.
Local news is a hard nut to crack. I still get the best results from a variety of bloggers that cover my home town which I can share via My Yahoo. The winning solution is going to be a hybrid of automated parsing (which has it’s own limitations) and crowd-sourced editorial that brings in the right people with the right set of incentives. Local Newspapers have the institutional clout to invite local participation but I’m still looking for a site that expands on the seemless integration of community blogs at the Lawrence-Journal (work incidentally started by EveryBlock’s founder, Adrian Holovaty).
Who’s going to write the CMS platform for the local newspaper that wants to go online?
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_c.png?x-id=d368a015-a531-438c-9a7c-12520f4713cb)

I’ve run into a few articles by Sarah from sarahintampa.com on ReadWriteWeb and have seen her referenced a few times so I went to check out her site and grabbed this graphic from a post about Create Debate.
Don’t have time to check out the service she’s talking about but I love the infographic which is brilliant.